Overview
On March 5th at the RSA security conference, the National Security Agency (NSA) released a reverse engineering tool called Ghidra. Similar to IDA Pro, Ghidra is a disassembler and decompiler with many powerful features (e.g., plugin support, graph views, cross references, syntax highlighting, etc.). Although Ghidra's plugin capabilities are powerful, there is little information published on its full capabilities. This blog post series will focus on Ghidra’s plugin development and how it can be used to help identify software vulnerabilities.
In our previous post, we leveraged IDA Pro’s plugin functionality to identify sinks (potentially vulnerable functions or programming syntax). We then improved upon this technique in our follow up blog post to identify inline strcpy calls and identified a buffer overflow in Microsoft Office. In this post, we will use similar techniques with Ghidra’s plugin feature to identify sinks in CoreFTPServer v1.2 build 505.
Ghidra Plugin Fundamentals
Before we begin, we recommend going through the example Ghidra plugin scripts and the front page of the API documentation to understand the basics of writing a plugin. (Help -> Ghidra API Help)

When a Ghidra plugin script runs, the current state of the program will be handled by the following five objects:
currentProgram: the active program
currentAddress: the address of the current cursor location in the tool
currentLocation: the program location of the current cursor location in the tool, or null if no program location exists
currentSelection: the current selection in the tool, or null if no selection exists
currentHighlight: the current highlight in the tool, or null if no highlight exists
It is important to note that Ghidra is written in Java, and its plugins can be written in Java or Jython. For the purposes of this post, we will be writing a plugin in Jython. There are three ways to use Ghidra’s Jython API:
Using Python IDE (similar to IDA Python console):

Loading a script from the script manager:

Headless - Using Ghidra without a GUI:

With an understanding of Ghidra plugin basics, we can now dive deeper into the source code by utilizing the script manager (Right Click on the script -> Edit with Basic Editor)

The example plugin scripts are located under /path_to_ghidra/Ghidra/Features/Python/ghidra_scripts. (In the script manager, these are located under Examples/Python/):

Ghidra Plugin Sink Detection
In order to detect sinks, we first have to create a list of sinks that can be utilized by our plugin. For the purpose of this post, we will target the sinks that are known to produce buffer overflow vulnerabilities. These sinks can be found in various write-ups, books, and publications.
Our plugin will first identify all function calls in a program and check against our list of sinks to filter out the targets. For each sink, we will identify all of their parent functions and called addresses. By the end of this process, we will have a plugin that can map the calling functions to sinks, and therefore identify sinks that could result in a buffer overflow.
Locating Function Calls
There are various methods to determine whether a program contains sinks. We will be focusing on the below methods, and will discuss each in detail in the following sections:
Linear Search - Iterate over the text section (executable section) of the binary and check the instruction operand against our predefined list of sinks.
Cross References (Xrefs) - Utilize Ghidra’s built in identification of cross references and query the cross references to sinks.
Linear Search
The first method of locating all function calls in a program is to do a sequential search. While this method may not be the ideal search technique, it is a great way of demonstrating some of the features in Ghidra’s API.
Using the below code, we can print out all instructions in our program:
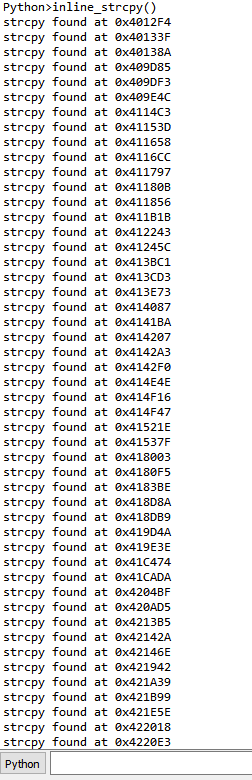
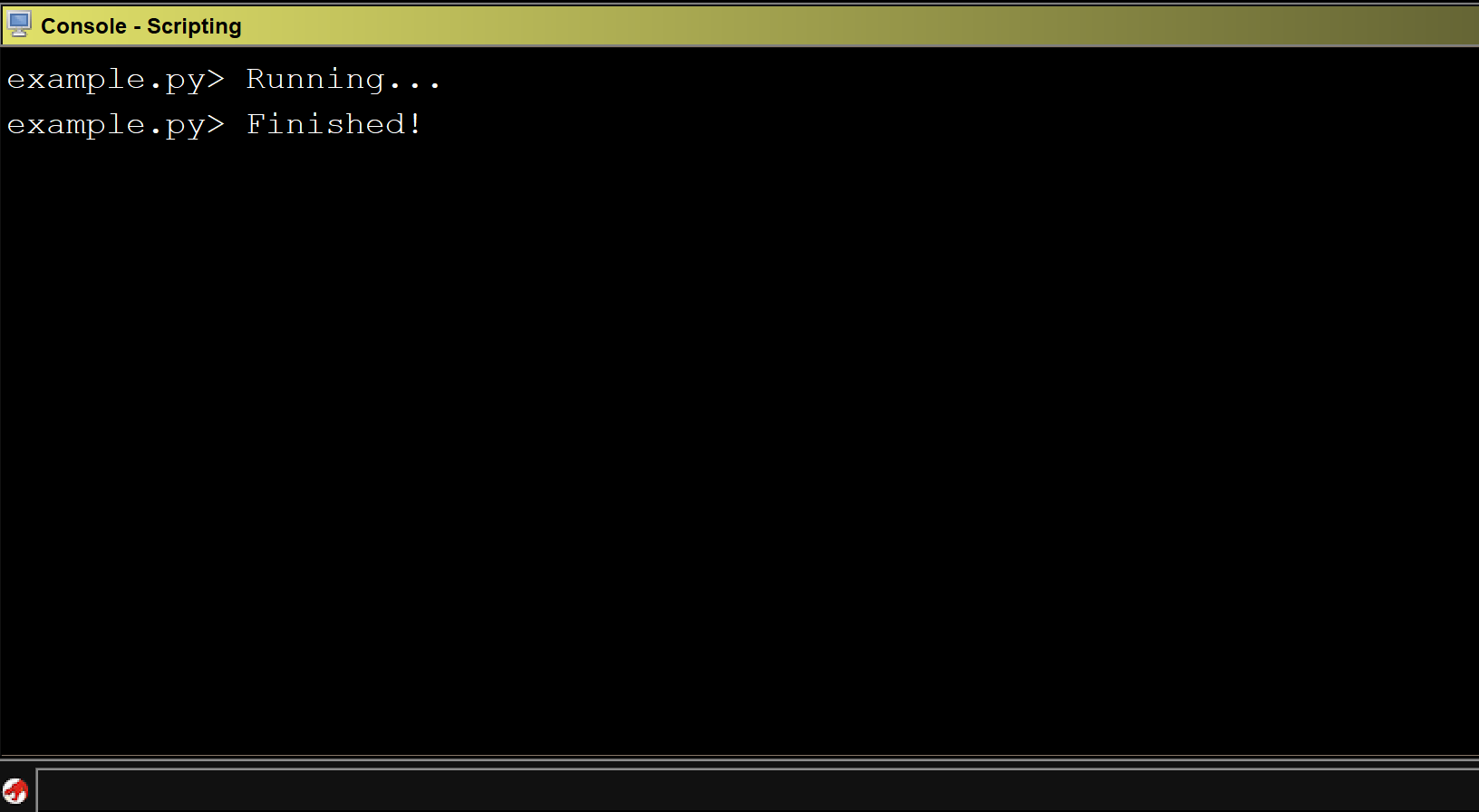
Running the above script on CoreFTPServer gives us the following output:

We can see that all of the x86 instructions in the program were printed out to the console.
Next, we filter for sinks that are utilized in the program. It is important to check for duplicates as there could be multiple references to the identified sinks.
Building upon the previous code, we now have the following:
Now that we have identified a list of sinks in our target binary, we have to locate where these functions are getting called. Since we are iterating through the executable section of the binary and checking every operand against the list of sinks, all we have to do is add a filter for the call instruction.
Adding this check to the previous code gives us the following:
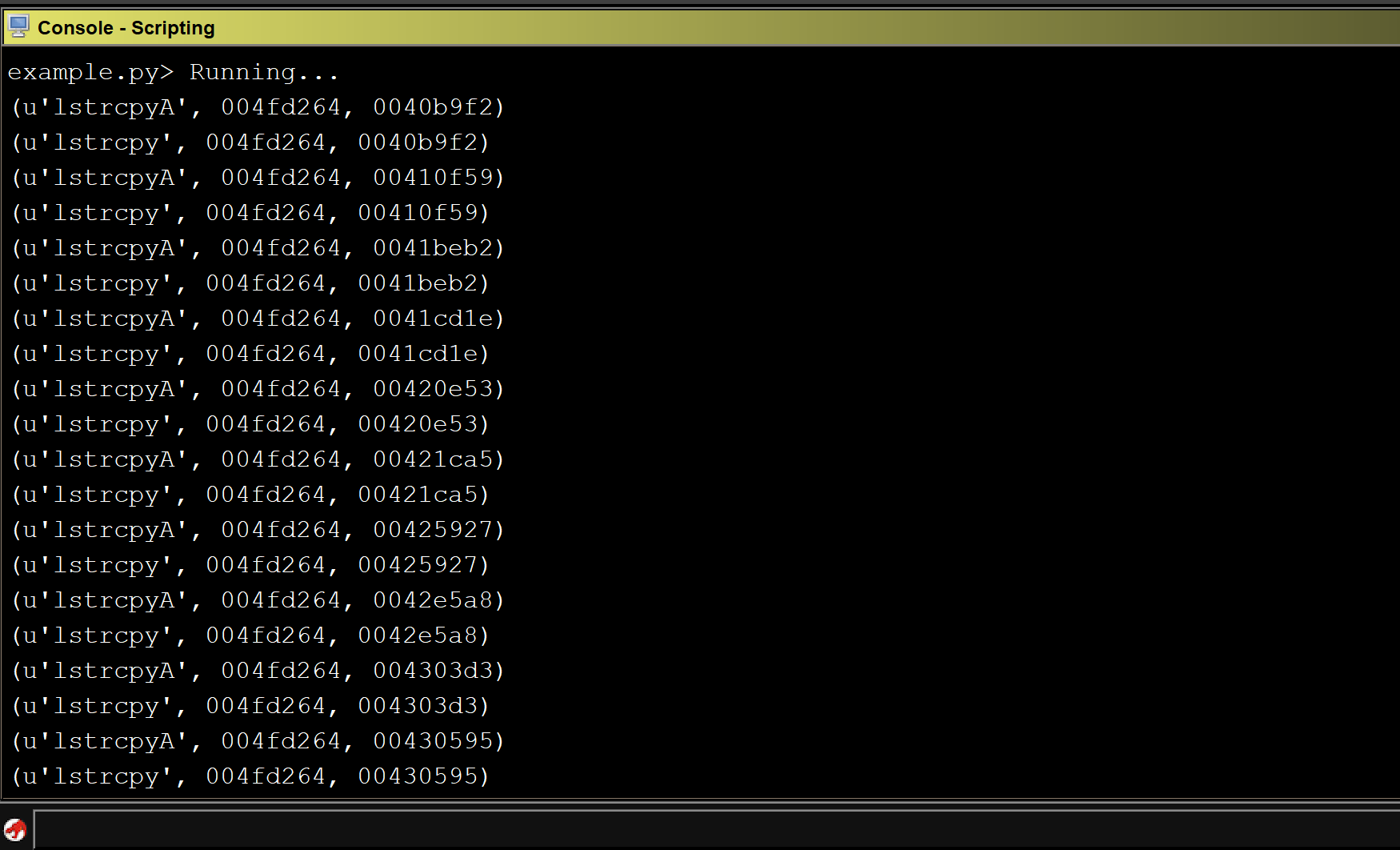
Running the above script against CoreFTPServer v1.2 build 505 shows the results for all detected sinks:
Unfortunately, the above code does not detect any sinks in the CoreFTPServer binary. However, we know that this particular version of CoreFTPServer is vulnerable to a buffer overflow and contains the lstrcpyA sink. So, why did our plugin fail to detect any sinks?
After researching this question, we discovered that in order to identify the functions that are calling out to an external DLL, we need to use the function manager that specifically handles the external functions.
To do this, we modified our code so that every time we see a call instruction we go through all external functions in our program and check them against the list of sinks. Then, if they are found in the list, we verify whether that the operand matches the address of the sink.
The following is the modified section of the script:
Running the modified script against our program shows that we identified multiple sinks that could result in a buffer overflow.

Xrefs
The second and more efficient approach is to identify cross references to each sink and check which cross references are calling the sinks in our list. Because this approach does not search through the entire text section, it is more efficient.
Using the below code, we can identify cross references to each sink:
Now that we have identified the cross references, we can get an instruction for each reference and add a filter for the call instruction. A final modification is added to include the use of the external function manager:
Running the modified script against CoreFTPServer gives us a list of sinks that could result in a buffer overflow:
Mapping Calling Functions to Sinks
So far, our Ghidra plugin can identify sinks. With this information, we can take it a step further by mapping the calling functions to the sinks. This allows security researchers to visualize the relationship between the sink and its incoming data. For the purpose of this post, we will use graphviz module to draw a graph.
Putting it all together gives us the following code:
Running the script against our program shows the following graph:

We can see the calling functions are highlighted in blue and the sink is highlighted in red. The addresses of the calling functions are displayed on the line pointing to the sink.
After conducting some manual analysis we were able to verify that several of the sinks identified by our Ghidra plugin produced a buffer overflow. The following screenshot of WinDBG shows that EIP is overwritten by 0x42424242 as a result of an lstrcpyA function call.

Additional Features
Although visualizing the result in a graph format is helpful for vulnerability analysis, it would also be useful if the user could choose different output formats.
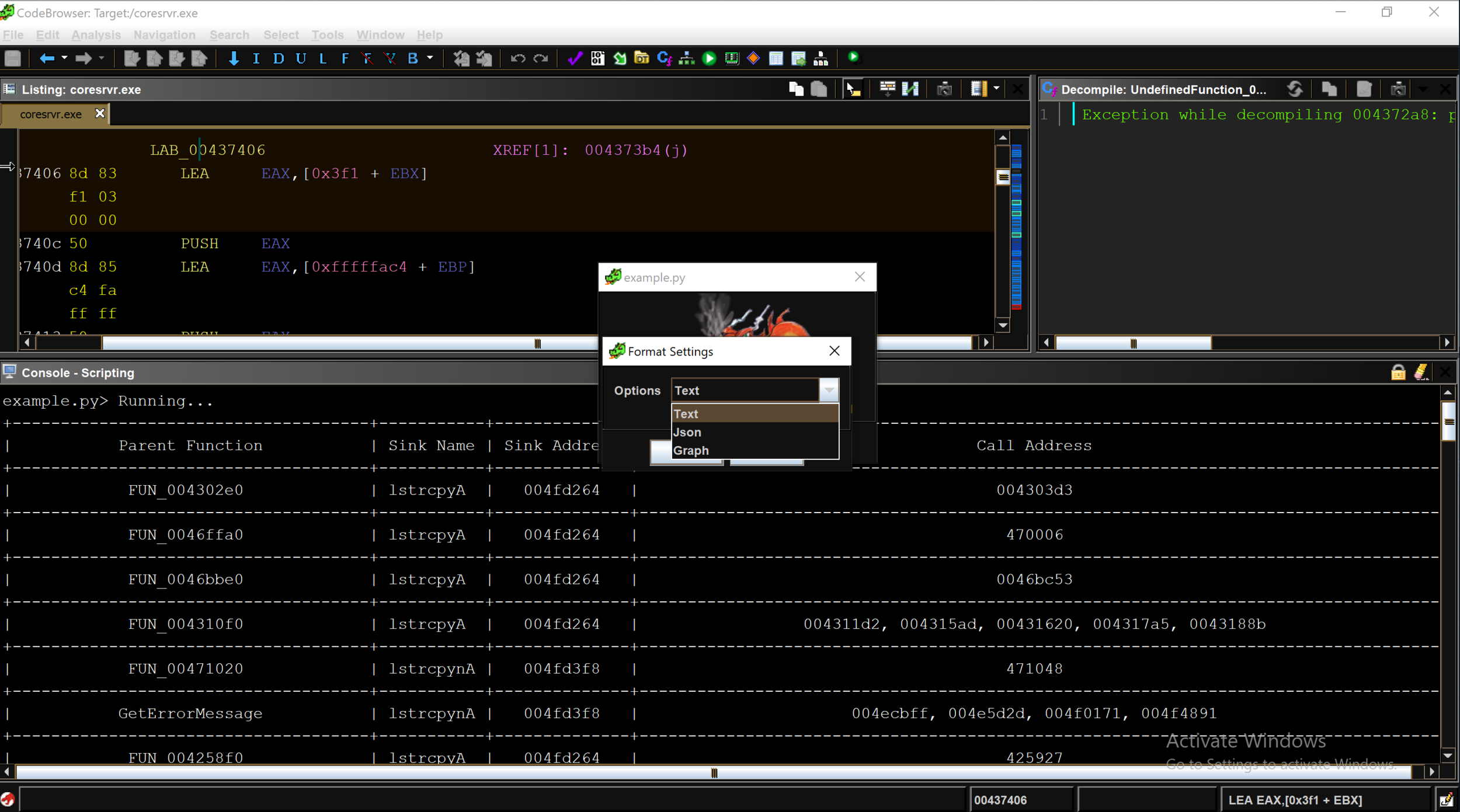
The Ghidra API provides several methods for interacting with a user and several ways of outputting data. We can leverage the Ghidra API to allow a user to choose an output format (e.g. text, JSON, graph) and display the result in the chosen format. The example below shows the dropdown menu with three different display formats. The full script is available at our github:
Limitations
There are multiple known issues with Ghidra, and one of the biggest issues for writing an analysis plugin like ours is that the Ghidra API does not always return the correct address of an identified standard function.
Unlike IDA Pro, which has a database of function signatures (FLIRT signatures) from multiple libraries that can be used to detect the standard function calls, Ghidra only comes with a few export files (similar to signature files) for DLLs. Occasionally, the standard library detection will fail.
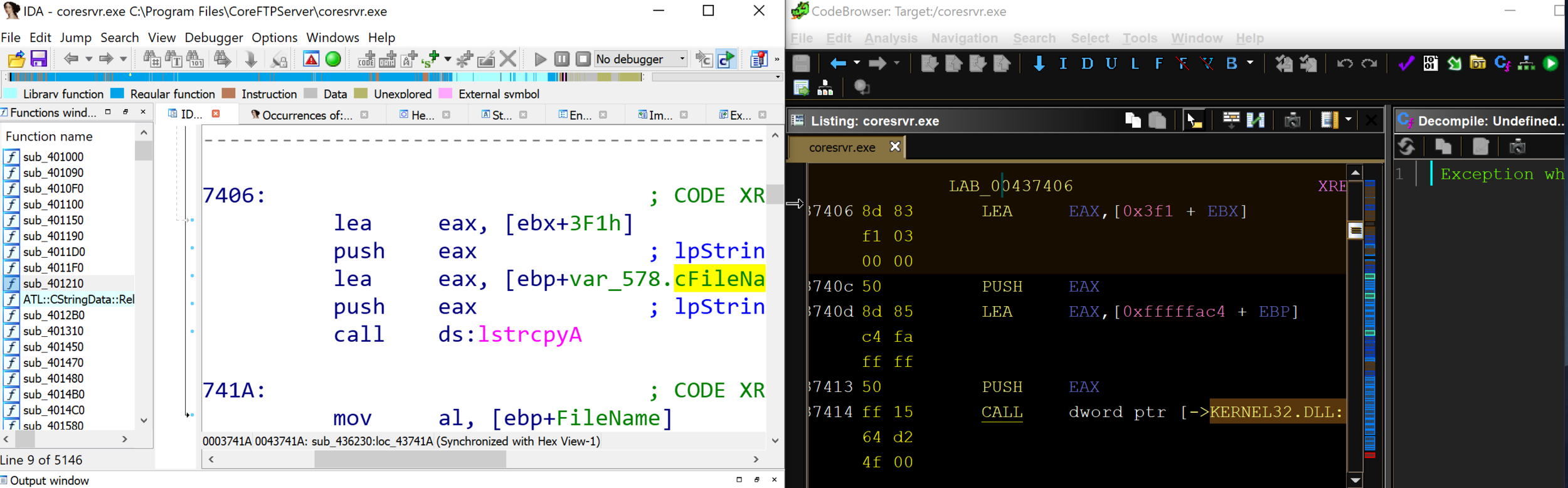
By comparing IDA Pro and Ghidra’s disassembly output of CoreFTPServer, we can see that IDA Pro’s analysis successfully identified and mapped the function lstrcpyA using a FLIRT signature, whereas Ghidra shows a call to the memory address of the function lstrcpyA.
Although the public release of Ghidra has limitations, we expect to see improvements that will enhance the standard library analysis and aid in automated vulnerability research.
Conclusion
Ghidra is a powerful reverse engineering tool that can be leveraged to identify potential vulnerabilities. Using Ghidra’s API, we were able to develop a plugin that identifies sinks and their parent functions and display the results in various formats. In our next blog post, we will conduct additional automated analysis using Ghidra and enhance the plugins vulnerability detection capabilities.